プライバシー保護技術を用いたスタンプサジェスト機能
LINEヤフーでは、LINEアプリのユーザーの好みにあったスタンプが提案される機能に、ユーザーのプライバシーを保護しつつ利便性を向上させるため、連合学習(Federated Learning)・差分プライバシー(Differential Privacy)と呼ばれる技術を導入しています。
詳しく見る 閉じる
LINEアプリ(以降、「アプリ」と記載)のトークルーム等でのスタンプ選択時に、高い精度でユーザーの好みにあったスタンプが提案される機能(以降、「スタンプサジェスト機能」と記載)を提供しています。
この機能の中で、ユーザーのプライバシーを保護しつつ利便性を向上させるため、連合学習(Federated Learning)・差分プライバシー(Differential Privacy)と呼ばれる技術を導入しています。この技術は、グローバルスタンダードな技術として確立しつつあり、LINEヤフーもこの分野で世界最先端の研究を行っています。
LINEヤフーはユーザーのプライバシー保護を重要視しています。今後、ユーザーのプライバシー保護とデータを活用した利便性向上の両立を図るため、これらの技術の研究開発を進め、幅広いサービスへの導入も検討してまいります。
以下では、これら技術を適用したスタンプサジェスト機能の仕組みやユーザーへのメリットをご説明します。
スタンプサジェスト機能とユーザに適したスタンプの推薦の必要性
スタンプサジェスト機能とは、トークルーム等で「おはよう」「ありがとう」などの文字を入力した際に、その意味に近いスタンプを推薦表示する機能です。この機能は以下のように実行されます。
・ユーザーは、アプリにスタンプデータをダウンロードします。このデータには、各スタンプに対して複数のキーワードが関連づけられています。
・アプリは、ユーザーがアプリに文字を入力した際、入力文字からキーワードを抽出します。
・その後、アプリはそのキーワードに合致したスタンプを推薦結果として表示します。
上記の処理は、すべてユーザーのスマートフォン等端末(以降、「ユーザー端末」と記載)で実行されます。
ここで、ユーザー一律で人気のスタンプを推薦候補としてしまうと、ユーザーの好みに合ったスタンプがサジェストされないため、ユーザーにとって利便性が十分ではありません。
そこで、ユーザーのスタンプ利用履歴からスタンプの利用傾向を学習し、各個人にあったスタンプを推薦する仕組みが必要になります。
スタンプの利用履歴は、大きく以下の2種類があります。
1.「スタンプの入手履歴データ」(購入や無料ダウンロード等)
2.「トークルーム等でのスタンプ閲覧・送信履歴のデータ」
スタンプサジェスト機能に導入されている連合学習・差分プライバシーと呼ばれる技術は、プライバシーの観点でとくに取り扱いを注意する必要のある2.の「トークルーム等でのスタンプ閲覧・送信履歴のデータ」を、可能な限りユーザー端末にて処理することで、当社サーバー(以降、「サーバー」と記載)が受け取る情報を制限し、プライバシーの保護につなげるものです(※1)。
なお、ユーザーがトークルームで入力したテキスト情報は、解析や学習に利用しておりません。
処理の概要
スタンプサジェスト機能の処理の流れを図1に示します(※2)。
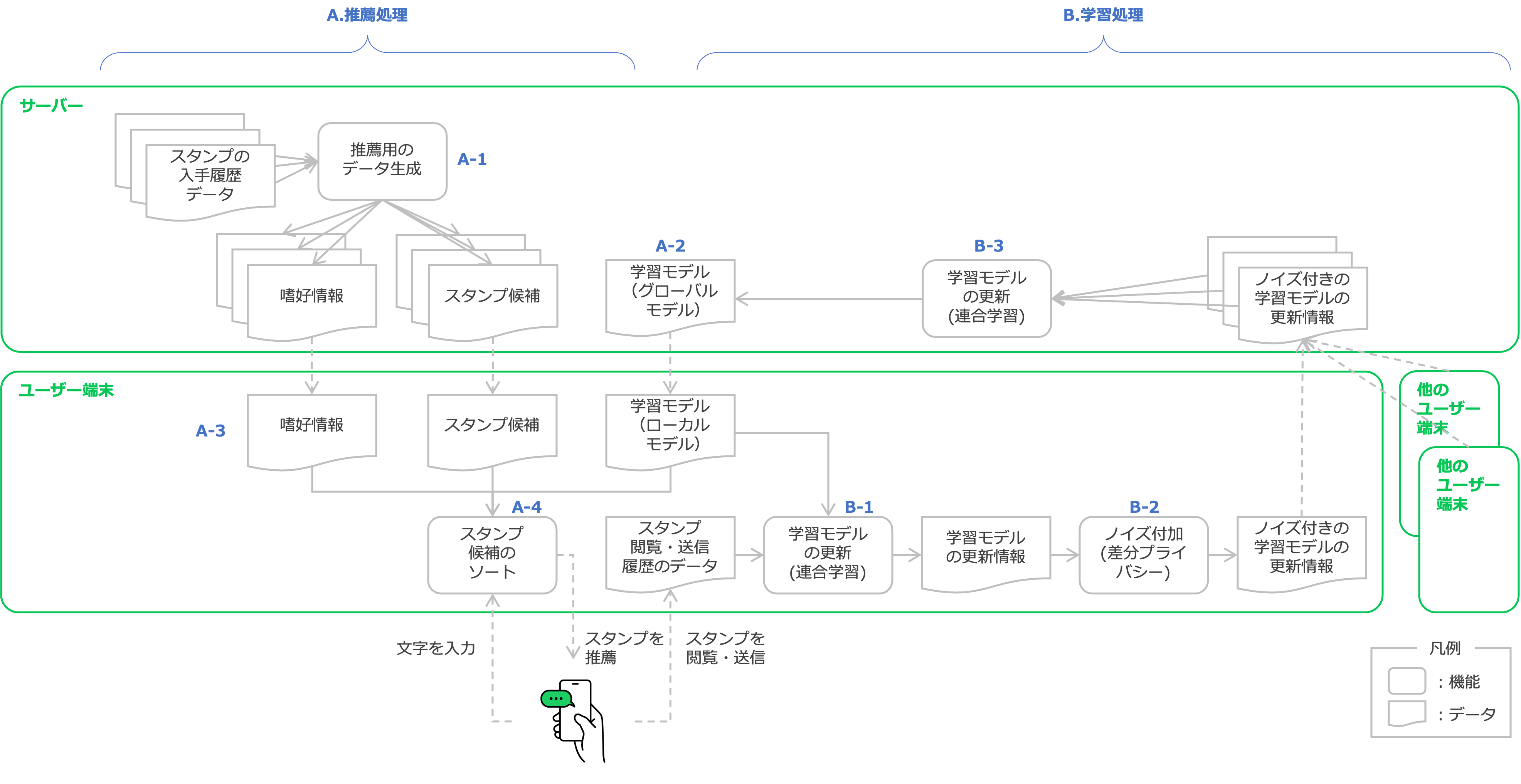 図1:スタンプサジェスト機能の処理概要
図1:スタンプサジェスト機能の処理概要
この機能は大きく「A. 推論処理」と「B. 学習処理」に分かれています。
まずは「A.推論処理」について説明します。
A-1. LINEヤフーのサーバーは、前述の「1.スタンプの入手履歴データ」から、「嗜好情報」と「スタンプ候補」を生成します。
・「嗜好情報」とは、ユーザーのスタンプに関する嗜好に関する情報です。この情報は、サーバーにて、ユーザーのダウンロードのログ(例:購入したスタンプ、無料スタンプやLINEスタンプ プレミアムのスタンプのダウンロード情報)から生成します。
・「スタンプ候補」とは、推薦候補となるスタンプです。各スタンプには、スタンプに関連する複数のキーワード情報が含まれています。
A-2. またサーバーは、後述する「B.学習処理」を実行し、スタンプの並び順を変えるための「学習モデル」(グローバルモデル)を生成・更新します(※3)。
A-3. アプリは「嗜好情報」「スタンプ候補」「学習モデル」をサーバーからダウンロードします。
A-4. アプリは、ユーザーがトークルーム等で文字を入力した際に、入力文字から事前に設定されているキーワードを抽出します。そして、キーワードに合致する「スタンプ候補」を抽出します。その後、「嗜好情報」と「学習モデル」を用いて、抽出した「スタンプ候補」を並べ替え、それらを表示します。これらの処理はすべてユーザー端末で行われます。
続いて、「B.学習処理」について説明します。
B-1. アプリは適切なタイミングで、都度ランダムに選択されたユーザーのアプリ上で、2.の「トークルーム等でのスタンプ閲覧・送信履歴のデータ」を用いて学習処理を行い、アプリ上の「学習モデル」(ローカルモデル)を更新します(※4)(※5)。
B-2. その後アプリは、差分プライバシー(Differential Privacy)と呼ばれる技術を用いて、処理結果(学習モデルの更新情報)に対してノイズを加えます。このノイズ付加の主な理由は、処理結果から実際に入力したスタンプをLINEヤフーのサーバーを含む他者から推定されることを困難にするためです。そして、ユーザーの識別子を削除した上でサーバーに送信します。
B-3. サーバーは、B-1でランダムに選択された複数のユーザーから得た処理結果(ノイズ付きの学習モデルの更新情報)を統合し、学習モデルを更新します(※6)。このようなサーバーとユーザー端末とで連携して学習処理する方法を、連合学習(Federated Learning)と呼びます。
以上のような処理によりLINEヤフーは、2.の「トークルーム等でのスタンプ閲覧・送信履歴のデータ」を受け取らなくとも学習モデルを更新でき、ユーザーが入力した文字に対して自分にあったスタンプをより上位に推薦表示できるため、ユーザーにとって選びやすくなります。
※1 本技術の適用時点では、既存の取り扱いデータを変更するものではなく、ただちにプライバシーの向上にはつながるものではありません。
※2 ここでは、例として「LINEスタンプ プレミアム」における、連合学習と差分プライバシーの処理の概要を記載しています。
※3 本機能のリリース開始時点で最初に配布される学習モデル(グローバルモデル)は、スタンプをランダムに並び替える(サーバーでの事前学習を行っていない)ものですが、ユーザーが受け取るスタンプ候補自体は個人化されているため、個々人にあったスタンプを利用することができます。
※4 アプリ側で行われる学習処理は、ユーザー端末がアイドル中かつ充電中の場合にのみ実行されます。
※5 この学習モデル(ローカルモデル)は、ユーザーに表示されたスタンプ候補のうち、どのスタンプが選択されたかという情報をもとに学習します。ユーザーが入力した文字の情報は利用しません。
※6 更新された学習モデル(グローバルモデル)は、再度ユーザーのLINEアプリに配布されます。これにより、A.の推論処理はより適切にスタンプを並び替えることができるようになります。